Building Vehique: The Architecture Behind a Conversational Auto Search Platform
Vehique is an AI-powered platform for car shopping and research. The core idea is replacing traditional, existing filter-based search with natural language conversation, and eventually automating the search process entirely through agents that search on behalf of users.
We started about eleven months ago. Since then it's been a mix of market research, product experiments, prototype builds, and a lot of trial and error to understand what actually works and what doesn't. All of this happened with limited resources, limited capital, and limited access to an industry that keeps its data and relationships fairly guarded. We didn't have the luxury of moving fast with certainty. Instead we moved carefully, tested cheaply, failed often, and learned from each iteration.
A few months ago we made the platform public. Since then we've seen over 3,000 monthly visitors actively searching on Vehique. That's where we are today.
This post explains how we built it, what architectural decisions shaped the product, what we learned running it in production, and the broader understanding we've developed about the market over the past year. There's a limit to what we can share publicly, but we wanted to be as open as possible. If you're reading this, we're genuinely grateful. And if any of it sparks questions or ideas, we'd be happy to discuss.
Vehique's conversational car search interface, where natural language meets automotive intelligence.
Source: vehique.ai ↗What This Post Covers
Building Vehique has meant wearing every hat at once. Product decisions, engineering work, user research, infrastructure choices. No handoffs. No separate teams. Just a continuous loop of building, testing, learning, and rebuilding.
This post documents what came out of that process.
What's covered:
Some of it might help others building in this space. Some of it is me thinking out loud. Either way, it felt worth writing down.
Why We Built a Conversational Interface
Traditional car shopping sites ask users to do a lot of mental translation. The burden goes far beyond just setting filters and browsing results.
To make a good decision, a buyer essentially needs to become an expert. They need to understand what different specs actually mean in practice, how certain engines or transmissions hold up over time, which model years to avoid, and what a fair price looks like in their specific market. This knowledge doesn't come for free. It requires hours of reading, comparing, and cross-referencing information that lives scattered across dozens of sources.
The search process itself is fragmented. Inventory is spread across multiple websites, each with different interfaces, different listing quality, and different levels of completeness. A car that shows up on one platform might not appear on another, or might appear with different photos and conflicting details. Buyers end up with browser tabs everywhere, trying to keep track of what they've already seen, what's worth revisiting, and what's already sold.
Finding a listing is only the beginning. Understanding whether that specific car is actually worth pursuing requires pulling in context from outside the search platform entirely. Reliability data from owner forums. Maintenance cost estimates from repair databases. Recall history. Common problems for that model year. Resale value trends. None of this lives in the listing itself. The buyer has to go find it, synthesize it, and figure out what it means for their situation.
And the situation matters. A car that makes sense for someone in a mild climate with a short commute might be completely wrong for someone facing harsh winters and long highway drives. Financial circumstances shape what's realistic. Family needs determine what's practical. Future plans influence whether buying or leasing makes more sense. All of these factors need to be weighed against each other, and the search platforms offer no help with that. The buyer carries the entire cognitive load of translating general information into personal relevance.
Most people don't do this alone anymore. They ask friends and family who might know more about cars. They post in online communities hoping for advice. Increasingly, they paste listings into ChatGPT or other AI tools and ask whether the price seems fair or if there are red flags they're missing. This has become a normal part of the process now, which says something about how inadequate the existing tools are. People are already reaching for AI assistance because the traditional search experience doesn't give them what they need.
All of this takes time, effort, and a willingness to learn things most people would rather not have to learn. Car buying becomes a part-time research project that stretches over weeks or months, filled with uncertainty about whether the effort is even pointing in the right direction.
We built Vehique because we think most of that burden can be lifted. The system should handle the translation, the research, the synthesis, and the personalization. Users should be able to describe what they need and get back answers that already account for context. That's the experience we're trying to build.
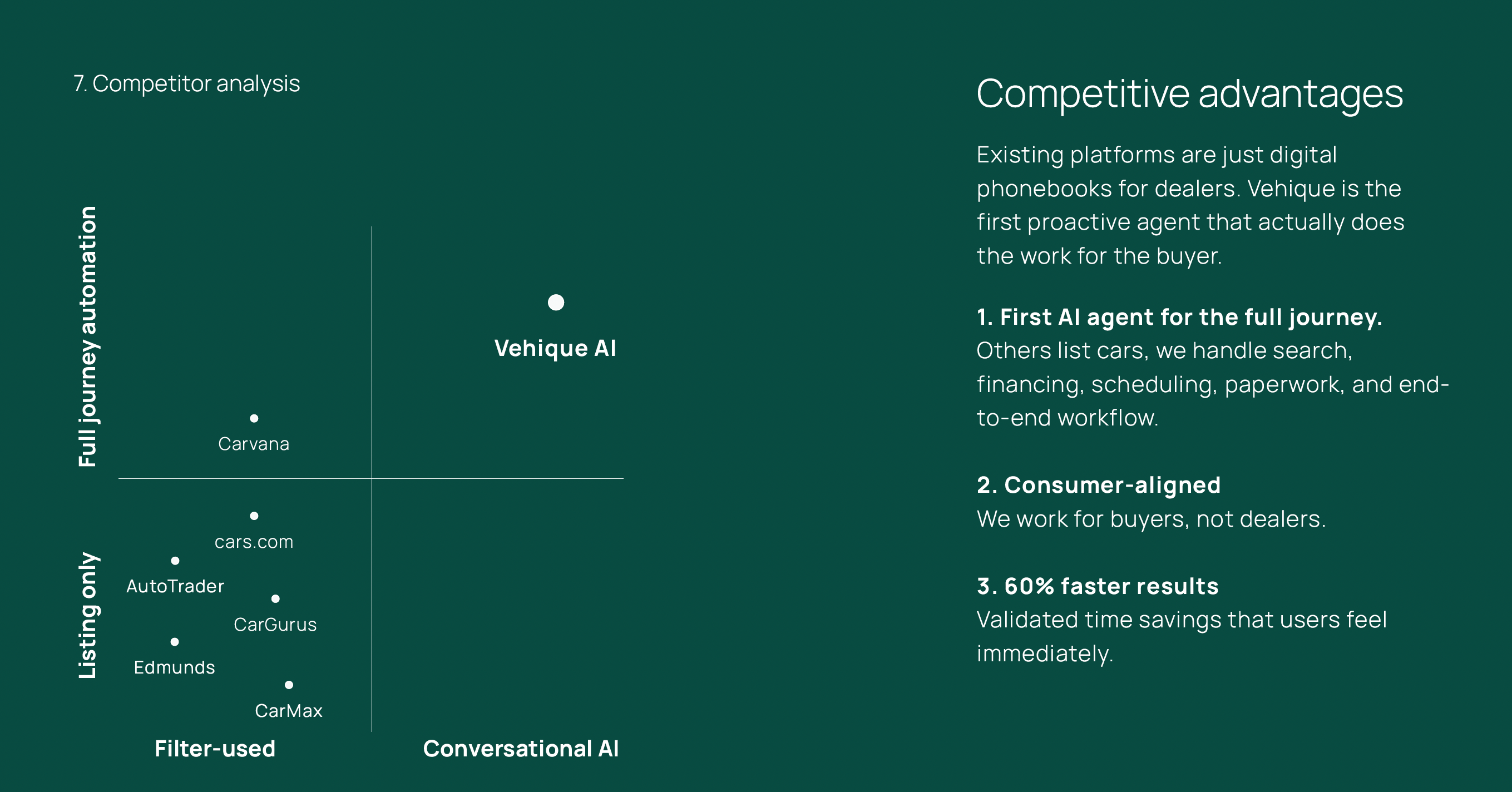
Competitor analysis from our pitch deck. A snapshot of how traditional platforms approach car search versus Vehique's conversational model.
Core Search Architecture
The search system transforms natural language queries into ranked vehicle listings through three main stages.
Intent parsing uses the fastest (Low latency) LLM to convert freeform text into structured parameters. When someone types "affordable SUVs near Boston," the parser extracts body type, price expectations relative to market norms, and location. It separates hard constraints that must be satisfied from soft preferences that influence ranking. When queries are too ambiguous, the system asks a single clarifying question rather than returning poor results. This happens in about fifteen percent of initial queries.
The inventory layer normalizes data from MarketCheck, which aggregates dealer feeds nationwide. Dealer data arrives inconsistently formatted, so we standardize colors, trims, mileage, and pricing into a common schema. We deduplicate on VIN when available and fuzzy match on attributes otherwise. Freshness matters because cars sell quickly, so we cache search results for fifteen minutes and use shorter windows for high-value vehicles.
Ranking scores candidates on price competitiveness, distance, mileage adjusted for age, model year, and listing quality. We apply diversity filtering to prevent results from being dominated by similar listings from the same dealer. Users consistently tell us that variety improves the experience even when it means individual results are marginally less optimal by pure scoring metrics.
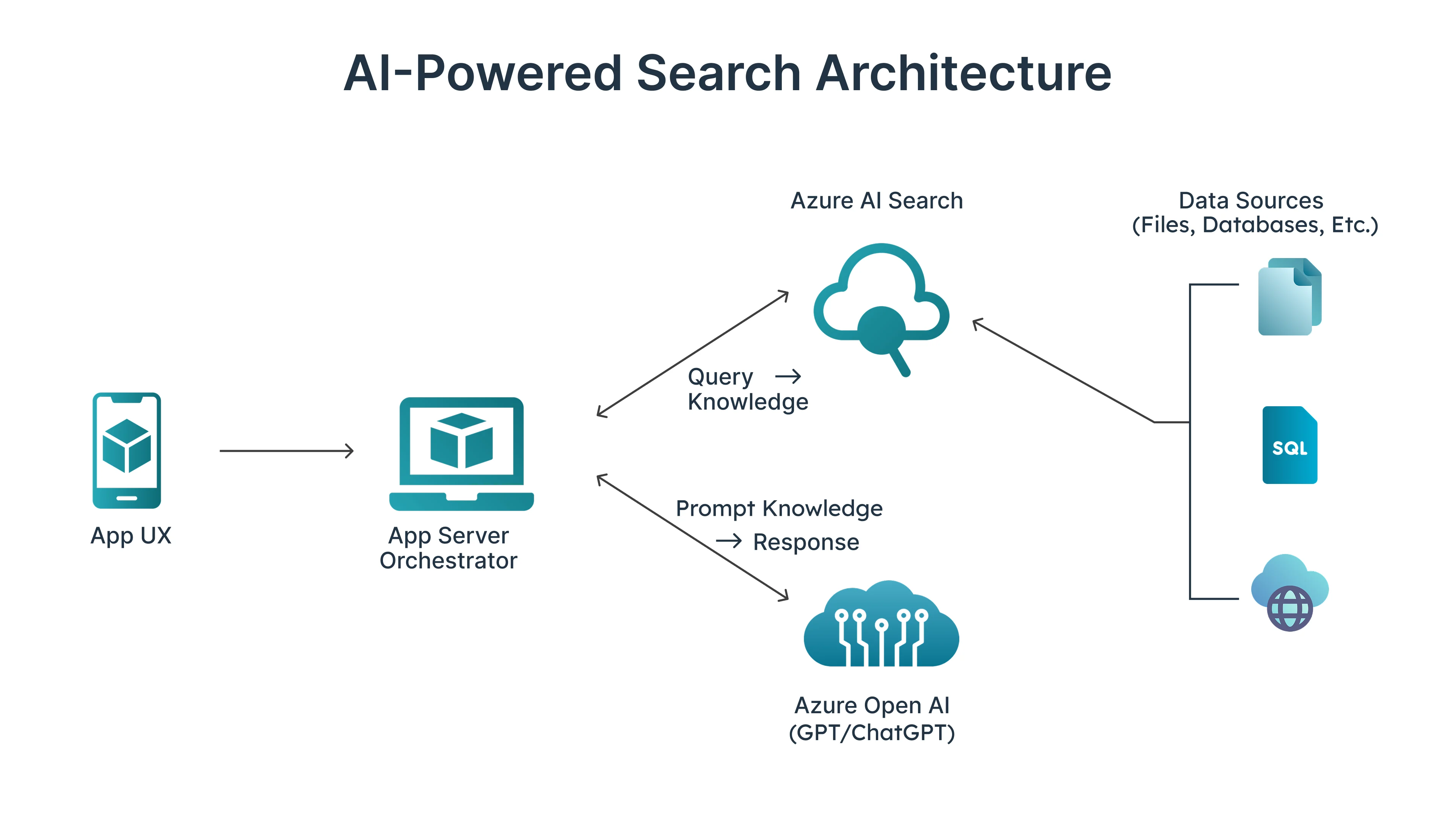
The core search architecture: Natural language queries flow through intent parsing, inventory normalization, and intelligent ranking to deliver personalized results.
Source: cdn.prod.website-files.com ↗Agent Orchestration and Deep Research
Search handles most queries, but users making a major purchase want more than listings. They want to know if a specific car is still available, what owners actually think of it, whether common problems affect that model year, and how the price compares to market value. Answering these questions requires gathering information from multiple sources simultaneously.
We built Deep Research as an orchestrated multi-agent workflow. When a user selects vehicles for comparison, we spin up four specialized agents that run in parallel and contribute different pieces of the picture.
The Inventory Agent fetches structured market data for the selected vehicles. This includes detailed specifications, pricing history, days on market, and how the listing compares to similar vehicles in the region. It also pulls market value estimates and calculates whether the asking price represents a good deal, a fair price, or a premium relative to comparable sales. The data comes from our normalized inventory layer and provides the factual foundation for comparison. Without this grounding in real market data, the other agents would lack context for evaluating what they find.
The Verification Agent acts as a real-time scraper that visits dealer vehicle detail pages directly. Aggregated feeds often lag behind reality, so this agent checks whether the listing is still active and extracts details that dealers mention on their websites but don't include in structured feeds. Things like "one owner," "clean CarFax," special financing offers, or recent price drops often appear only on the dealer page. The agent handles anti-bot protections through rotating proxies and request throttling, though about sixty percent of attempts still get blocked. When verification succeeds, it adds meaningful confidence to the recommendation.
The Research Agent uses an external research engine to search the web for owner sentiment and reliability information. The workflow targets specific content types rather than generic web results. We search for Reddit threads discussing ownership experiences, YouTube reviews from automotive journalists and owners, reliability reports from Consumer Reports and J.D. Power, and forum discussions about common problems with specific model years. The agent synthesizes findings into key strengths, weaknesses, and known issues that would take a buyer hours to research manually.
The Voice Agent uses Vapi to physically call dealerships for real-time availability checks. This is currently live in production. When verification through web scraping fails or when we need confirmation before a user commits to visiting a dealer, the voice agent places an automated call, navigates the dealership phone tree, and asks a representative whether the specific vehicle is still on the lot. The agent handles hold times, transfers between departments, and varied response formats. Call results feed back into the comparison with verified availability status.
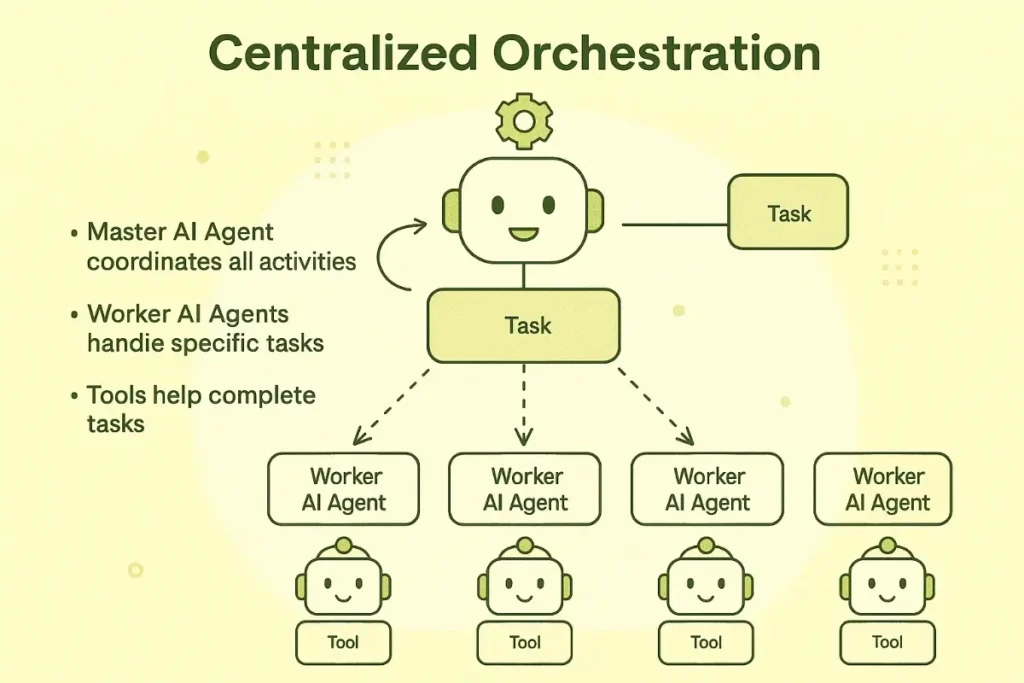
Multi-agent orchestration: Four specialized agents (Inventory, Verification, Research, and Voice) work in parallel to gather comprehensive vehicle insights.
Source: dextralabs.com ↗All four agents stream progress through Server-Sent Events so users see exactly what's happening. The full research process takes between thirty and ninety seconds depending on complexity. Showing the work explicitly builds trust in a way that a generic loading spinner cannot. Users report that watching agents actively gather information makes them confident the results represent genuine research rather than cached summaries.
After all agents complete, we synthesize their outputs into a unified comparison. Each vehicle receives a match score incorporating value, condition, verified availability, reliability reputation, and data completeness. The comparison surfaces specific findings like recurring transmission issues mentioned across Reddit threads or a price drop detected by the verification agent. Users get both the structured comparison and the reasoning behind our recommendations.
Vehique Autopilot
Not everyone wants to actively search for a car. Some buyers know roughly what they want but don't have time to check listings daily, monitor price drops, or research every promising option that appears. They want a reliable partner doing that work in the background and surfacing only what's worth their attention.
Vehique Autopilot, currently in development, flips the model from active searching to passive discovery. Instead of users coming to Vehique with queries, Autopilot comes to users with matches.
The setup process collects preferences through a short conversation. Beyond the basics like budget, body type, and location, we ask personalization questions that help the system understand priorities. How important is low mileage versus newer model year? Does brand reputation matter? Is there flexibility on color or is that a dealbreaker? These answers create a preference profile that guides ongoing searches.
Once configured, users deploy agents that search on their behalf. The agents run scheduled searches multiple times per day, scanning new inventory as it hits the market and re-evaluating existing listings when prices change. When something matches the preference profile, the agent runs it through Deep Research automatically, pulling market data, owner sentiment, and reliability information. If the vehicle passes quality thresholds, the user gets a notification with the full research package ready to review.
The experience resembles having a knowledgeable friend who works at a dealership and texts you whenever something good comes in. Users check their matches when convenient, review the research the agent already completed, and decide whether to pursue or pass. The agent learns from these decisions and refines future recommendations.
The ambition is making car buying feel less like a second job. Today, finding a good deal requires constant vigilance across multiple sites, quick action when something appears, and hours of research to validate each option. Autopilot handles the vigilance and validation so users can focus on the decision itself. We want buying a car to feel like choosing from a curated shortlist rather than hunting through an endless marketplace.

The vision behind Autopilot: AI agents that see the market through your preferences, surfacing only what matters.
Source: lummi.ai ↗Evaluation and Quality Monitoring
AI-powered features can degrade in ways that are difficult to notice without systematic measurement. A parsing change might cause certain query types to fail silently. A ranking adjustment might improve averages while hurting important edge cases. Agent orchestration adds additional failure modes when any single agent times out or returns poor results.
We maintain about two hundred test queries with defined expected behaviors and run this suite before deploying changes. Online monitoring tracks click-through rates, refinement frequency, and session depth to detect sudden changes following deployments. For agent workflows specifically, we track completion rates for each agent type, result quality scores, and user engagement with synthesized comparisons.
Human review happens weekly on a sample of fifty sessions. We manually evaluate whether parsing worked correctly, whether agent outputs were accurate and useful, and whether the overall experience met reasonable expectations. This catches issues that aggregate metrics miss and informs prioritization.

Quality monitoring: Like Jared's SWOT analysis in Silicon Valley, we obsess over metrics and decision-making frameworks to continuously improve search quality.
Source: vox.com ↗Production Reliability
Running conversational search in production requires managing tradeoffs between speed, quality, and cost. We've made progress but significant challenges remain.
Search latency is our primary constraint. The target is under two seconds end-to-end, but we don't hit that consistently. Intent parsing alone takes four hundred to eight hundred milliseconds when calling hosted LLM APIs. Add inventory lookup, ranking, and response formatting, and we're often closer to two and a half seconds on cache misses. Users notice. Agent workflows are more forgiving since Deep Research and Autopilot run in the background without someone watching a loading spinner.
For failures, we follow graceful degradation. If the inventory API times out, we return cached results with a staleness notice. If individual agents fail during research, we complete with available data and note which sources we couldn't reach. This works acceptably but feels like a band-aid rather than a solution.
Cost scales with usage. Search costs about a penny per query in API calls. Deep Research runs closer to fifty cents when including external research queries and Vapi minutes. At 3,000 monthly users these numbers are manageable. At ten times that scale, they become a problem worth solving.
Challenges and Open Questions
Several architectural decisions we made early now feel like constraints worth revisiting.
The biggest is our dependency on hosted LLM APIs for latency-sensitive operations. Every search query requires a parsing call that adds half a second or more of network latency before any actual work begins. I've been thinking about whether self-hosted models running on optimized inference infrastructure could cut that significantly. Smaller fine-tuned models for intent parsing specifically, deployed on hardware tuned for low latency, might get parsing under a hundred milliseconds. The tradeoff is operational complexity and upfront infrastructure cost, but at scale it might be cheaper than per-token API pricing anyway.
More broadly, I'm questioning whether real-time search needs this much AI in the hot path at all. Simple keyword and filter queries could bypass LLM parsing entirely and go straight to the inventory layer. We'd reserve the sophisticated natural language understanding for cases that actually need it. The heavy AI work would shift toward Deep Research and Autopilot, where response time is measured in minutes rather than seconds and quality matters more than speed. Users waiting for Autopilot results overnight don't care if processing took ten seconds or sixty. Users typing a search query care a lot.
Streaming and speculative execution are worth exploring. Rather than waiting for complete intent parsing before starting inventory lookup, we could begin fetching results based on partial parse confidence and refine as the full interpretation completes. This adds complexity but could make the perceived experience feel significantly faster.
On the agent side, the sixty percent failure rate on dealer page verification bothers me. Anti-bot protections are getting more sophisticated and our current approach of rotating proxies and request throttling feels like an arms race we'll eventually lose. Browser automation with proper fingerprinting might improve success rates but increases infrastructure cost and latency. Partnerships with dealers for direct API access would solve this entirely but requires business development work outside the engineering domain.
Voice agent reliability is another open question. Vapi handles the mechanics well, but dealership phone systems vary wildly. Some have simple menus, others have complex IVR trees, some go straight to voicemail during business hours. Our current success rate on getting a human who can answer availability questions is around seventy percent. The remaining thirty percent represents either failed calls or inconclusive responses. I'm not sure yet whether the path forward is better prompt engineering for the voice agent, calling at optimal times based on dealership patterns, or accepting that voice verification works best as one signal among many rather than a definitive source.
The industry is moving fast on inference optimization. Techniques like speculative decoding, continuous batching, and quantized models are making self-hosted inference more viable for production workloads. I want to experiment with deploying a small intent-parsing model on something like vLLM or TGI to see if we can get the latency wins without sacrificing too much accuracy. If parsing quality drops, we could use the fast model for simple queries and fall back to a larger hosted model for complex ones.
What We Learned
Data quality determines the ceiling for search quality. We invested more time in normalization and deduplication than any other component, and that investment continues to pay off. But working with data from third-party APIs taught us a harder lesson about control. When your entire product depends on data you don't own, you're building on a foundation you can't fully trust. API formats change. Coverage has gaps. Freshness varies by source. You spend engineering time working around limitations instead of improving the product. It's been a valuable learning experience but also a clear signal about where we need to go.
Building on established data platforms like MarketCheck got us to market faster than collecting inventory ourselves. That was the right tradeoff for proving the concept. But the path to something remarkable probably requires more control over the data layer. We're thinking about this on multiple fronts. Partnerships with dealers that let them post inventory directly to Vehique would give us fresher data and create relationships that support features like Autopilot. Ethical scraping across the roughly 170,000 dealership websites in the United States could give us coverage and freshness independent of any single aggregator. Self-hosted inventory infrastructure would let us define our own schema, update frequency, and quality standards. None of this is simple, but owning more of the data stack seems necessary for the product we actually want to build.
Agent orchestration benefits from strong contracts between components. Each agent has defined inputs, outputs, and timeout behaviors. When one agent fails, others can complete independently, and synthesis handles partial data gracefully. This architecture made it possible to add the voice agent without touching the other three.
Showing work builds trust. Users engage more patiently with visible progress than with loading states, and they rate results higher when they can see the research that went into recommendations. Transparency about what the system is doing matters as much as the quality of what it produces.
Why We're Building This Way
Vehique exists because we believe the AI era should deliver real value worth paying for. We launched as a consumer product with a freemium model, but our focus from day one has been premium users who want something genuinely better than free alternatives. The goal isn't to capture attention with a free tool and figure out monetization later. The goal is to build something good enough that people happily pay for it.
This shapes every product decision. When we evaluate a feature, the question isn't whether it increases engagement metrics. The question is whether it solves a real problem well enough that someone would pay to have it solved. Deep Research exists because verifying a car's reliability takes hours of manual work and that time has value. Autopilot exists because monitoring the market daily is tedious and most people would rather delegate it. These aren't engagement plays. They're services.
The business model has a second layer we haven't built yet. Dealership partnerships represent a natural revenue stream that other car marketplaces have proven works. Dealers pay for leads and visibility. We intend to pursue that eventually, but with a clear constraint: the consumer experience stays untouched. Recommendations will never favor dealers who pay more. Search results won't be polluted with promoted listings. The moment we compromise consumer trust for dealer revenue, we become just another marketplace. That's not what we're building.
We've tried to outline our vision openly in this post, but honestly it's bigger than what fits here. We have ambitions for what car buying could look like when AI handles the tedious parts and humans focus on the decisions that matter. We're genuinely excited to see how far this can go. If any of this resonates and you want to build with us or explore partnerships, we'd love to talk.
What's Next
Right now we're focused on two things. Making Autopilot smarter and more reliable. And building personalization that actually learns what you want over time. Everything else can wait.
We're also looking for the right partners. Building a better car buying experience at scale probably means working with established players who share the vision. If you're at a company that finds this interesting, we're open to conversations. We don't have all the answers and we're not pretending to. But we're learning fast and genuinely excited about where this is going.
One last thing. I've been saying "we" throughout this post, but I should be honest. Vehique is just me right now. Solo founder, late nights, lots of coffee. The "we" felt right because I'm actively looking for a cofounder. Not someone who just checks boxes on technical skills or business experience, but someone who looks at this space and sees what I see. The possibilities. The ways car buying could actually feel good instead of exhausting. If that's you, reach out.
And if I'm being fully transparent, there is one other team member. My cat Floppy, who sits with me past midnight while I debug API calls and write docs like this one. She doesn't contribute much to the codebase, but the moral support counts for something.
Worst case, I learn a lot. Best case, we change how people buy cars.
Gemechu (Founder)
The real team behind Vehique: Floppy, our Chief Moral Support Officer, monitoring the late-night debugging sessions. She may not write code, but the emotional support is invaluable.
Share this article
If you found this useful, share it with others
Gemechu Taye
Founder
Building the future of AI-powered car shopping at Vehique. On a mission to make finding your perfect vehicle effortless.
hello@vehique.ai